Feature #4509
open
EPG content from "Subtitle" to "Content type"
0%
Files
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 Updated by saen acro almost 9 years ago
Updated by saen acro almost 9 years ago
- File Заснемане.PNG Заснемане.PNG added
- File Заснемане2.PNG Заснемане2.PNG added
- File Заснемане3.PNG Заснемане3.PNG added
- File Заснемане4.PNG Заснемане4.PNG added
- File Заснемане5.PNG Заснемане5.PNG added
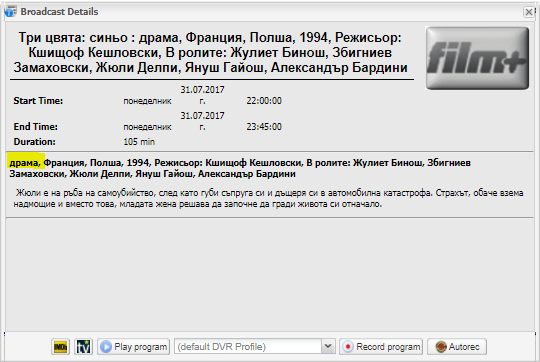
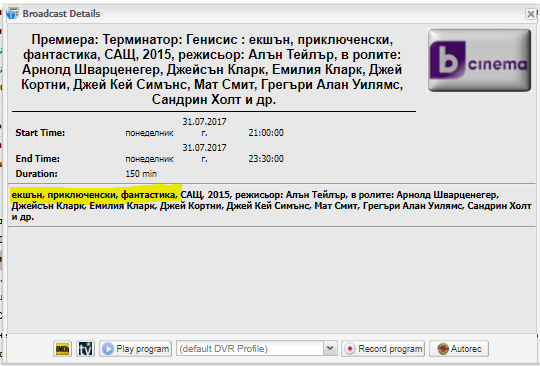
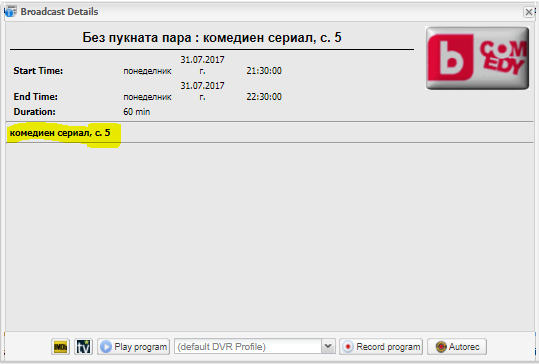
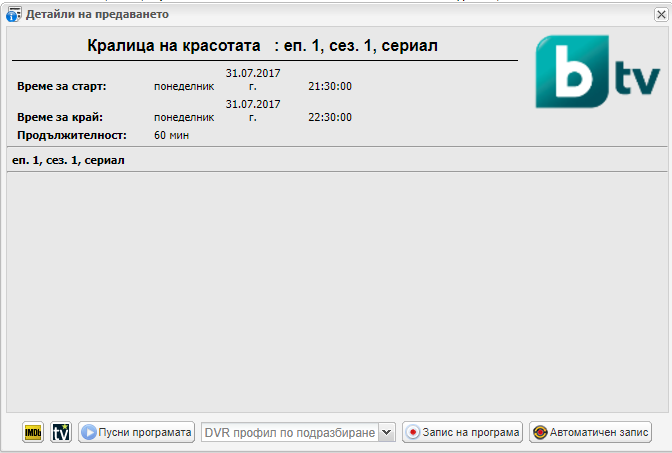
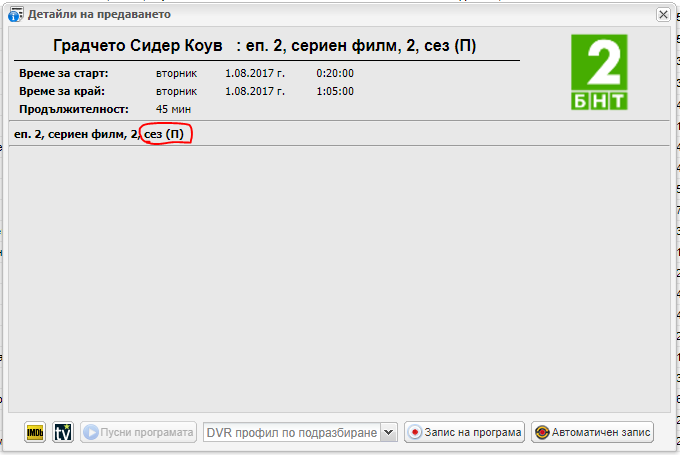
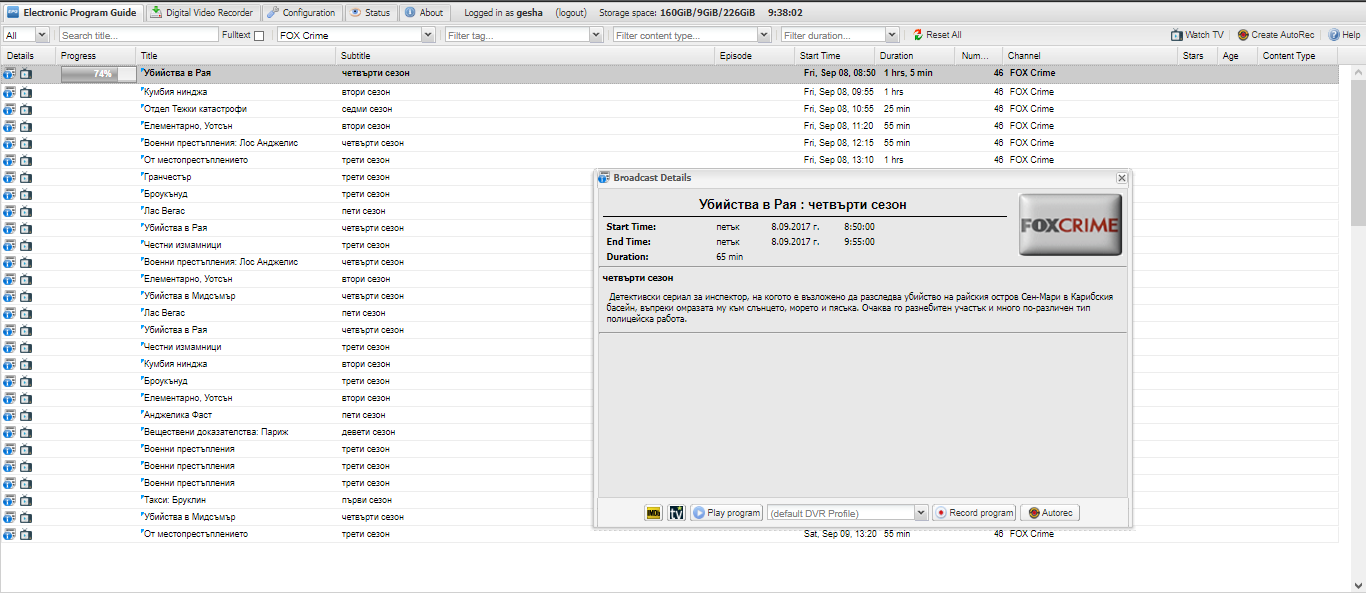
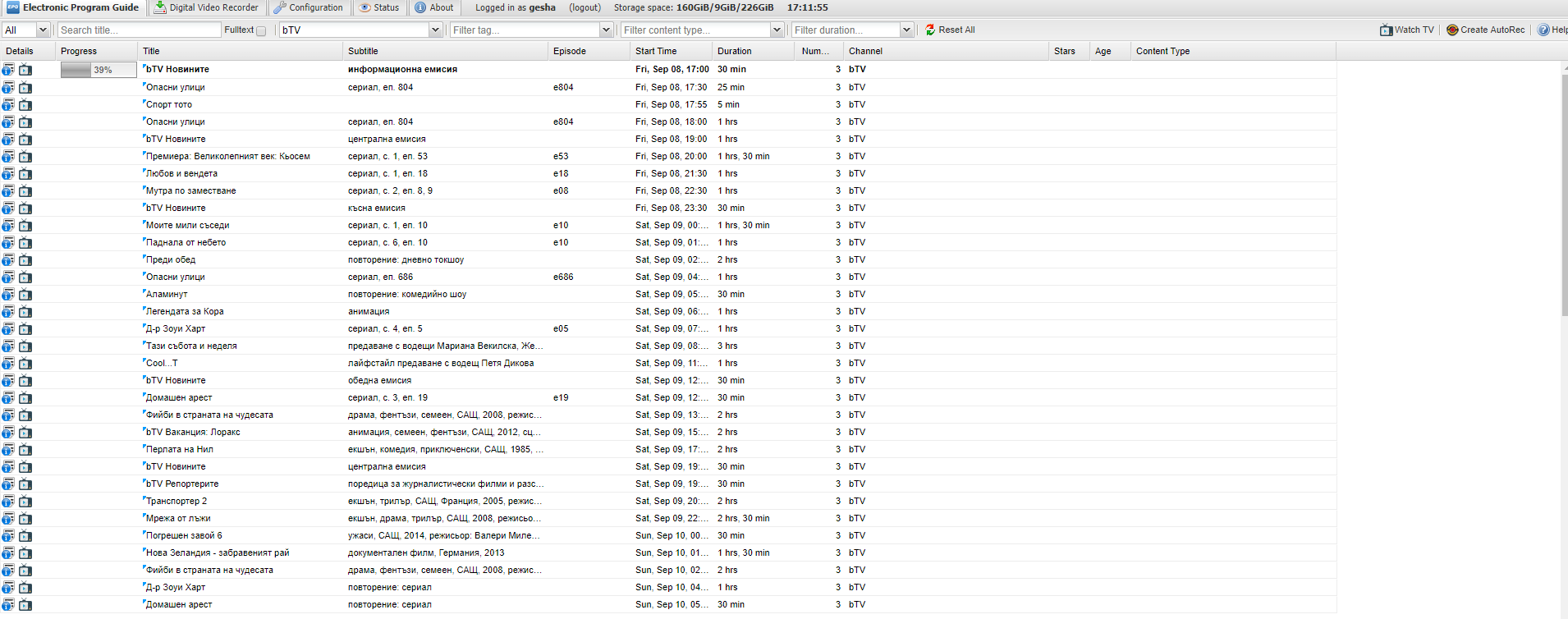
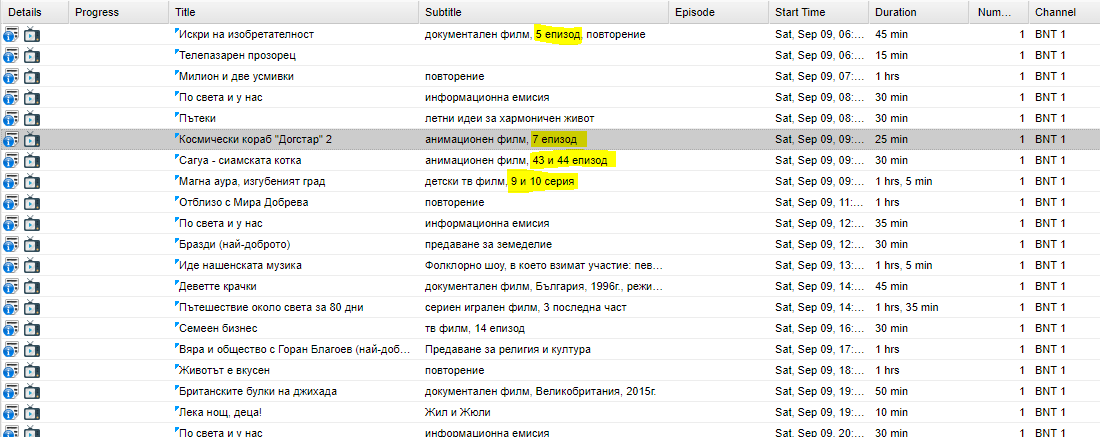
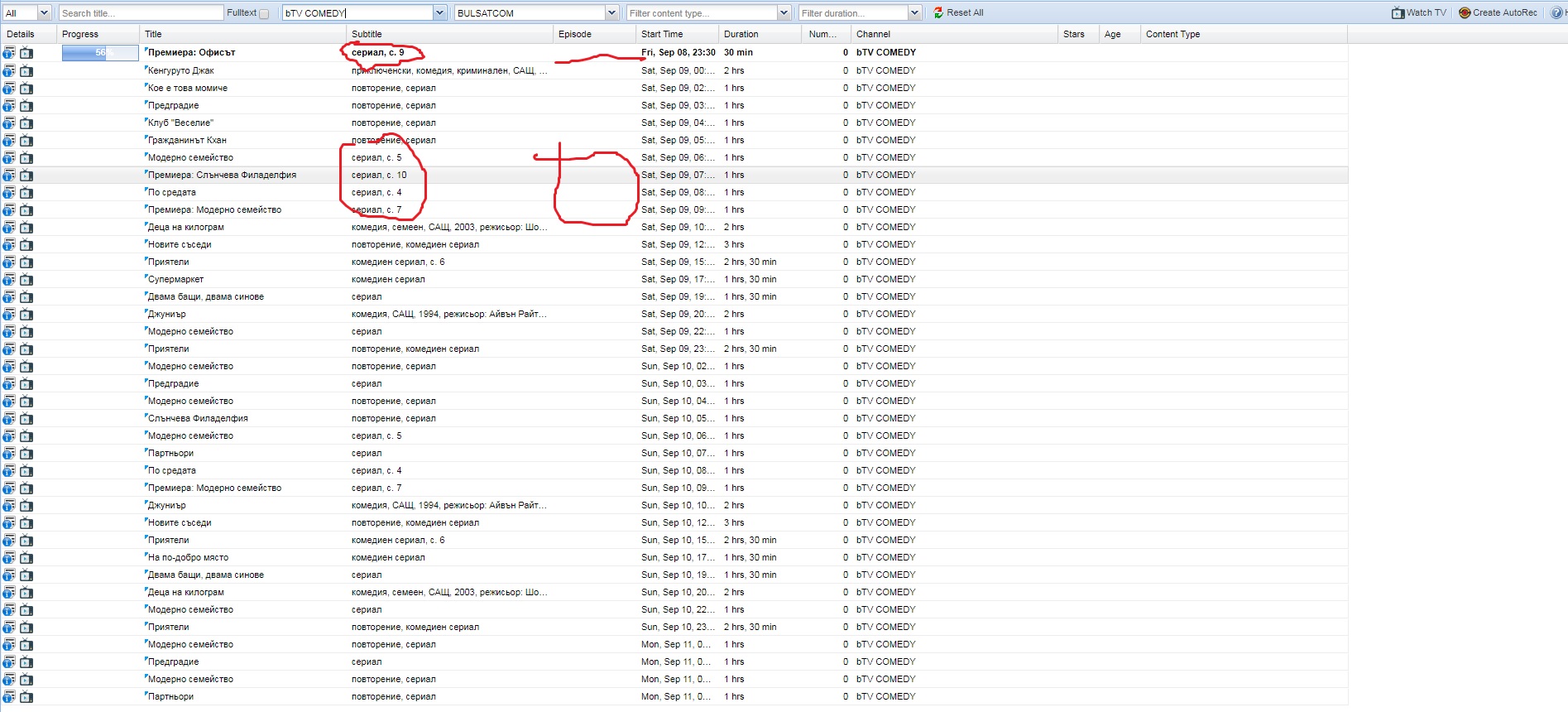
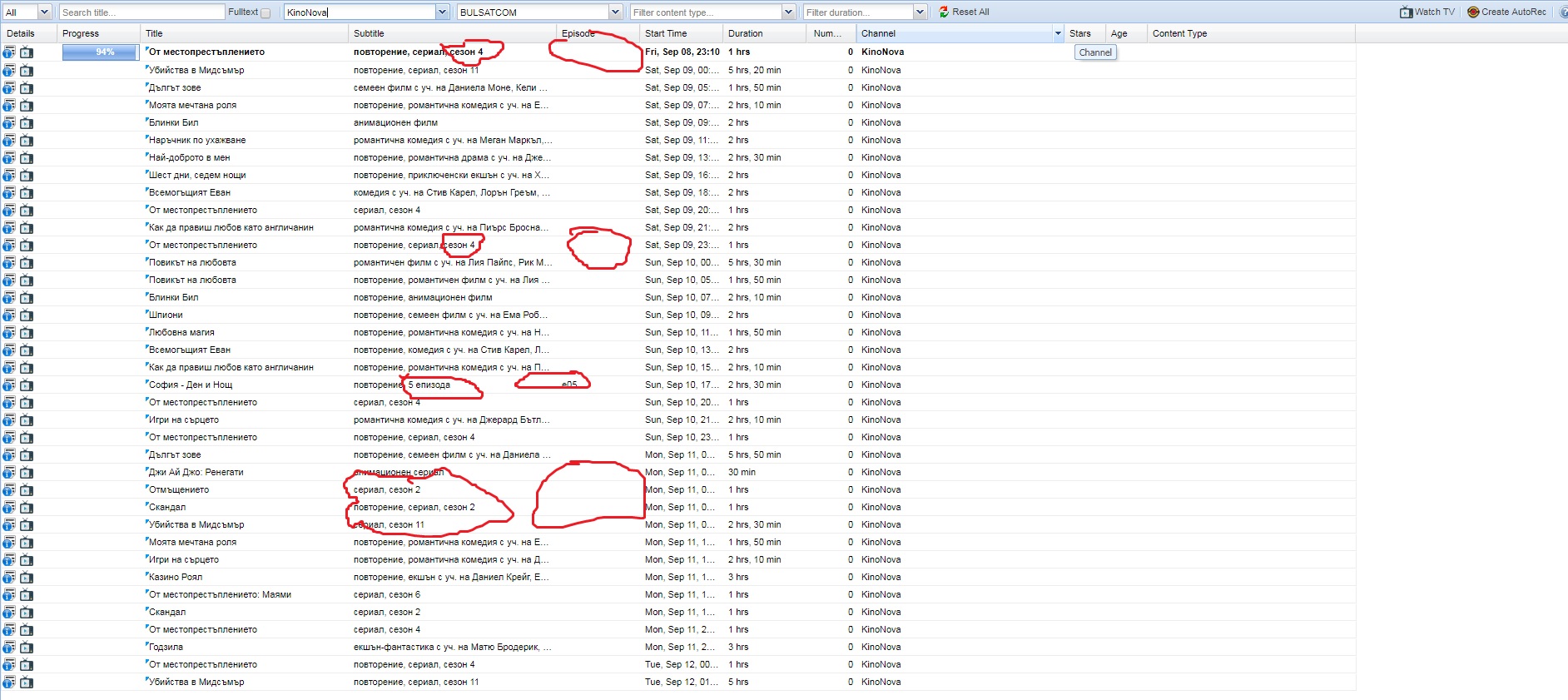
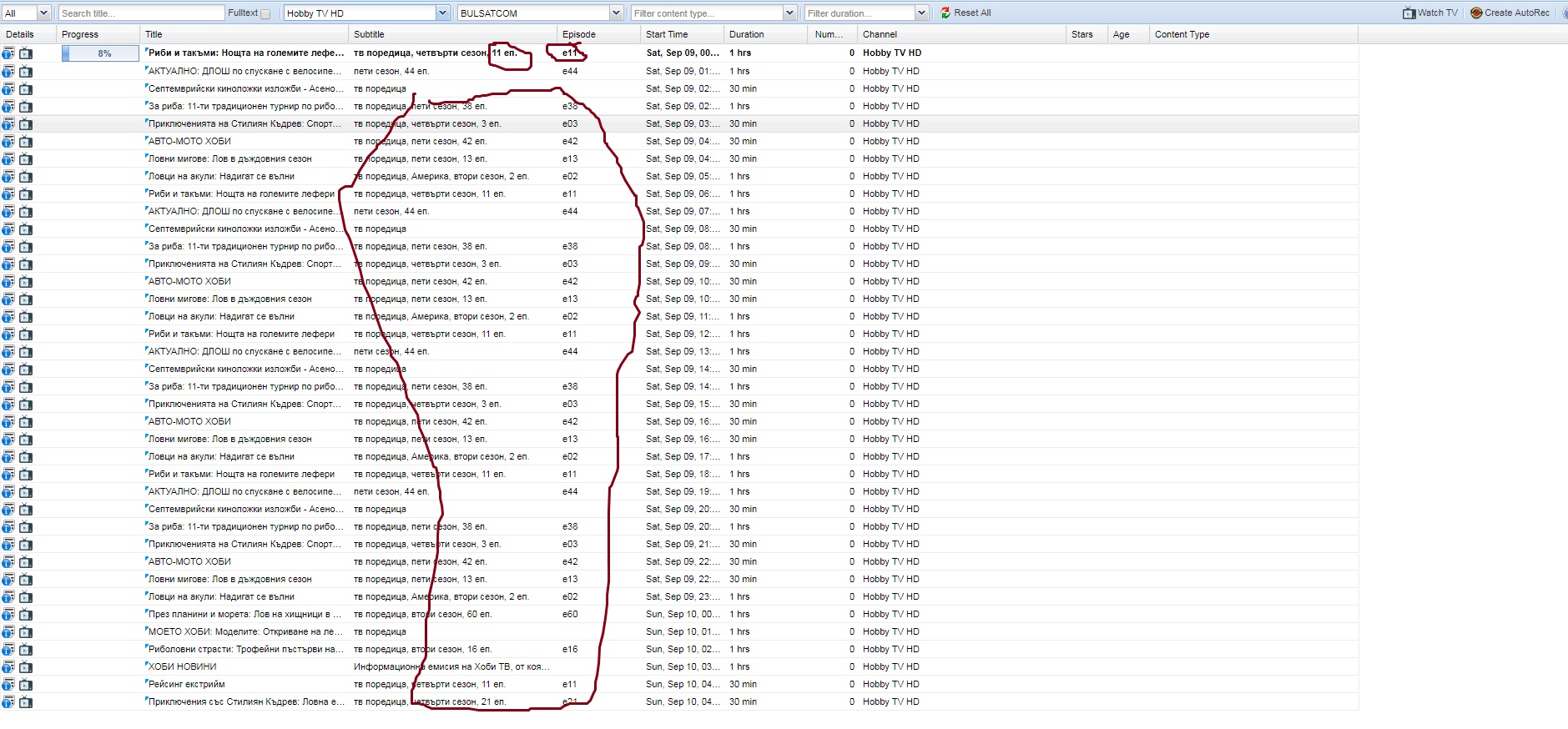
Some of local operators put Content type Episode in beginning of Subtitle
example in pictures
Is it possible content betwin comas to be used as filling content in Episode and Content type
then it is very easy for DVR to record without duplication
 Updated by Gabor Kovacs almost 9 years ago
Updated by Gabor Kovacs almost 9 years ago
saen acro wrote:
Some of local operators put Content type Episode in beginning of Subtitle
example in picturesIs it possible content betwin comas to be used as filling content in Episode and Content type
then it is very easy for DVR to record without duplication
I have the same issue, the episode number is in the subtitle, would be useful to extract it somehow into the correct field.
 Updated by Em Smith almost 9 years ago
Updated by Em Smith almost 9 years ago
Possible dup #4389 ("Regex in EIT grabber")?
Updated by Em Smith almost 9 years ago
I am assuming you are using "Bulsatcom Bula 39E" grabber?
I'm trying to work out two separate regular expressions that might help for season/episode, one for grabbing season and a separate one for matching episode that might work with a parser I'm working on.
Sorry if these questions sound obvious, but...
To confirm: "Сезон" is Season, "Епизод" is Episode.
Example 4 seems easy to parse, "episode 1, season 1" But in example 5 it seems to be saying "ep 2" and then "2, season" (rather than season 2). Am I right that sometimes it's "2, season" and sometimes "season 2"? I assume the words after "episode 2" is the genre in that example.
In example 3, it appears episode is abbreviated to purely letter "С." Does that abbreviation always mean episode?
Would you be able to paste the words used from a couple of examples and maybe just a couple of complete descriptions for season/episode?
Also, I noticed that you have dates such as ", 2015" and ", 1994". Is that the original air date (date movie was created)? If you type ", [0-9][0-9][0-9][0-9]" (comma, space) in to the EPG and hit "fulltext" then does it match correctly movies, or does it generate false matches with dramas and other programmes? Does the word after the year in example 2/3 mean something useful?
Thanks.
Updated by saen acro almost 9 years ago
Em Smith wrote:
I am assuming you are using "Bulsatcom Bula 39E" grabber?
No meter this is for some transponders with simulcrypt
I'm trying to work out two separate regular expressions that might help for season/episode, one for grabbing season and a separate one for matching episode that might work with a parser I'm working on.
Sorry if these questions sound obvious, but...
To confirm: "Сезон" is Season, "Епизод" is Episode.
Yes correct
Example 4 seems easy to parse, "episode 1, season 1" But in example 5 it seems to be saying "ep 2" and then "2, season" (rather than season 2). Am I right that sometimes it's "2, season" and sometimes "season 2"? I assume the words after "episode 2" is the genre in that example.
Operator owners and his personal have low IQ and result is following
In example 3, it appears episode is abbreviated to purely letter "С." Does that abbreviation always mean episode?
No it mean "Сезон" Season but who know can be "Серия" Episode, again IQ-ed personal do not have own standards for redundancies.
Would you be able to paste the words used from a couple of examples and maybe just a couple of complete descriptions for season/episode?
What word do you need, Ill will type it for you.
Also, I noticed that you have dates such as ", 2015" and ", 1994". Is that the original air date (date movie was created)? If you type ", [0-9][0-9][0-9][0-9]" (comma, space) in to the EPG and hit "fulltext" then does it match correctly movies, or does it generate false matches with dramas and other programmes? Does the word after the year in example 2/3 mean something useful?
Thanks.
You mean word "Режисьор" aka Director
similar is "В ролите" aka Starring
Updated by Em Smith almost 9 years ago
Which grabbers do you have enabled in configuration->channel->epg grabber modules?
Do you have a couple of example where "c." means episode and an example where it means season?
Your screenshots are good, but if you copy+paste from tvheadend a couple of examples with season/episode and one with episode only in case Google translate is using a different character mapping. I noticed your screenshots sometimes have "сез" and sometimes "сез." (with a period) so a few more examples will help find other differences.
Are Сезон and Епизод always in lowercase (сезон and епизод)?
Updated by saen acro almost 9 years ago
- File Заснемане6.PNG Заснемане6.PNG added
- File Заснемане7.PNG Заснемане7.PNG added
- File Заснемане8.PNG Заснемане8.PNG added
EIT: DVB Grabber + Bulsatcom: Bula 39E (same as first but on another PID)
are enabled modules.
Use Bing translate to compare https://www.bing.com/translator
In Bulgarian language "Серия" and "Епизод" have same meaning.
Foreign words in language, correct should be "Епизод, Еп. Е."
But correct typing by rules of language is other thing.
Only thing with is on place as separator is commas ;)
сезон 1, епизод 13, драма, романтичен, САЩ, 2014
Season 1, Episode 13, drama/romantic, USA, 2014
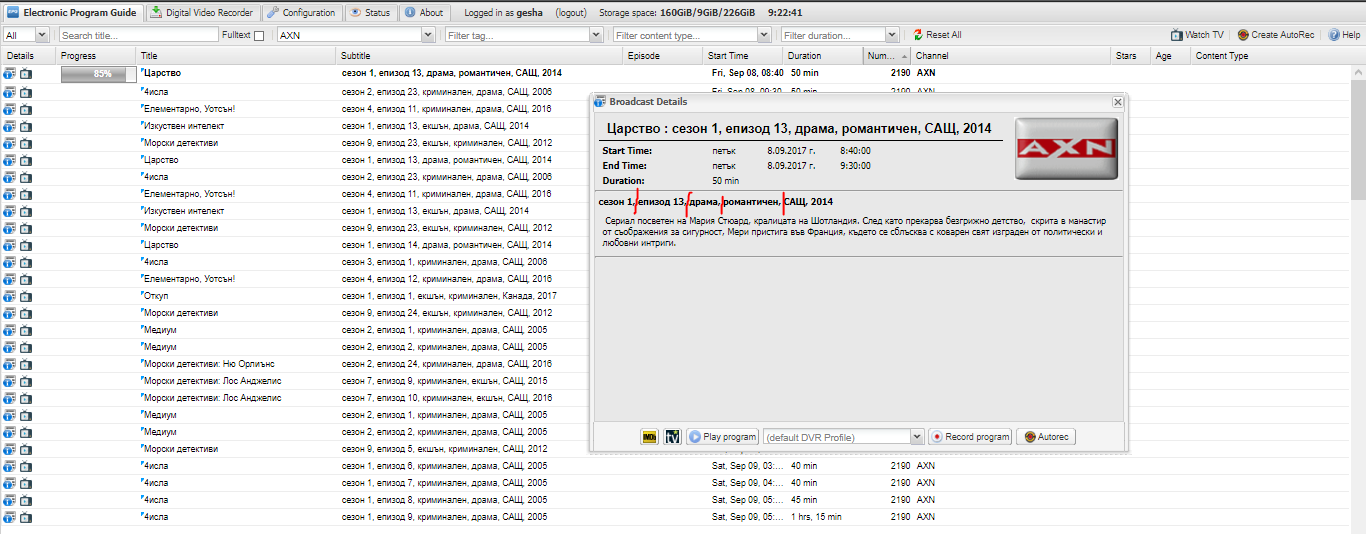
And something harder
сериал, еп. 45, 46
"еп. 45, 46" must be read as "еп. 45 and 46" two series.
(it's more easy to type it one and not copy to second event)
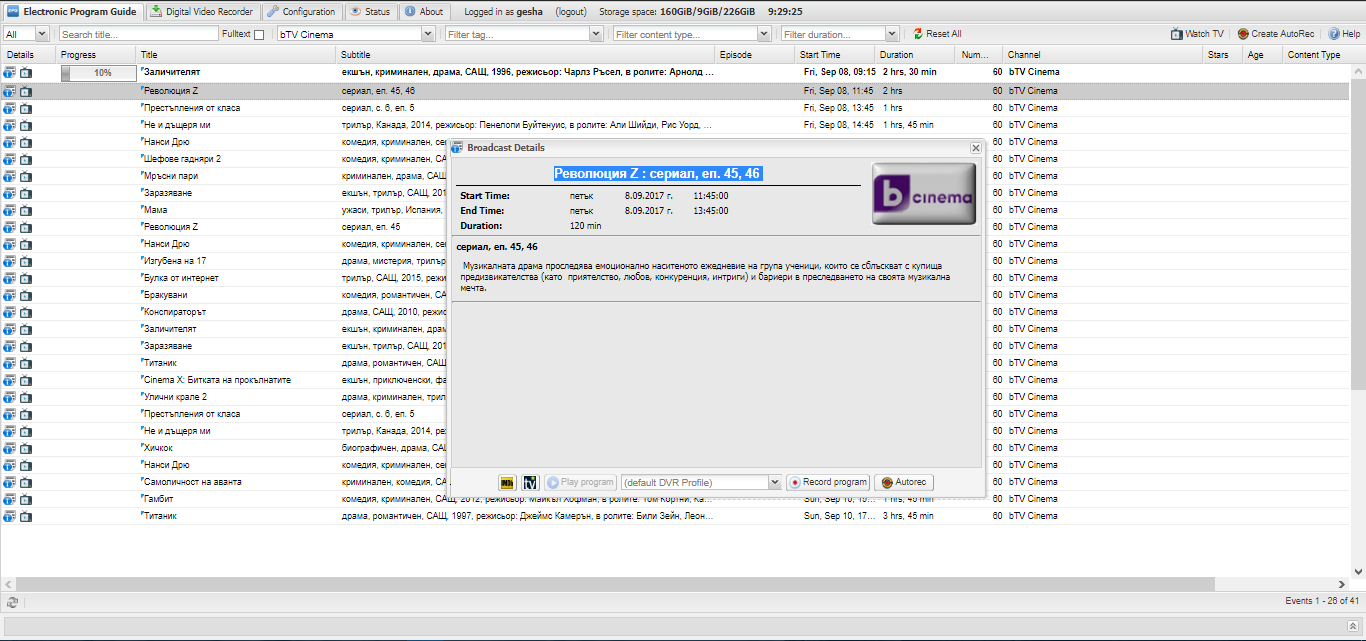
And even more harder.
четвърти сезон
fourth season, no series №, because is easy not to type.
Updated by Em Smith almost 9 years ago
- File 0001-eit-Initial-Bulsatcom_39E-configuration.-4509.patch 0001-eit-Initial-Bulsatcom_39E-configuration.-4509.patch added
I've attached a patch. It needs the very latest tvheadend built.
Once built, go to Configuration->Channel->EPG Grabber Modules.
On "Bulsatcom" click "Scrape Episode".
On "EIT DVB Grabber" click "Scrape Episode" and in "Configuration to use" enter "Bulsatcom_39E".
You should see lines in the log file similar to:
[ INFO] tbl-eit: scraper Bulsatcom_39E attempt to load config "Bulsatcom_39E"
[ INFO] tbl-eit: scraper Bulsatcom_39E loaded config "Bulsatcom_39E"
Then EPGGrabber->Trigger OTA EPG Grabber.
I can't test the patch properly since I don't get your channels, but I've tested the configuration regex against the strings you provided and they seem to be ok. However it's possible you get nothing or bad results. Let me know and paste the bad match text in the note.
However, I still do not understand when "с." means season and when episode. I've assumed if it is at end of title then it is episode.
Patch does not handle "еп. 45, 46" and will use "45". I don't think tvheadend allows multiple episodes in same broadcast.
Updated by saen acro almost 9 years ago
I will test almost immediately if/when approved in github ;)
currently tvheadend_4.3-448~g2f07ea0
Just idea, is there a way to be created "situation dictionary" inside UI.
Later will be easy to be shared with friend.
I understand that there is a very lot of language situations to be described.
Updated by saen acro almost 9 years ago
- File Заснемане9.PNG Заснемане9.PNG added
Test positive
but just for easy I "touch"
touch /usr/share/tvheadend/data/conf/epggrab/eit/scrape/Bulsatcom_39E
and attach content from patch
{
"season_num": [
"сезон ([0-9]+)",
"сез.? ([0-9]+)",
"еп. [0-9]+,.*, ([0-9]+), ?сез"
],
"episode_num": [
"епизод ([0-9]+)",
"еп. ([0-9]+)",
"с. ([0-9]+)$"
],
"airdate": [
", ([0-9][0-9][0-9][0-9])"
]
}
result in attachment
do we can do same modification with "Content type"
Updated by saen acro almost 9 years ago
- File Заснемане10.PNG Заснемане10.PNG added
and some not accepted corrections by patch
Updated by Em Smith almost 9 years ago
Try this replacement. This will detect the new format "ep 43 & 44" but will only see it as "ep 44".
{
"season_num": [
"сезон ([0-9]+)",
"сез.? ([0-9]+)",
"с. ([0-9]+), еп.",
"еп. [0-9]+,.*, ([0-9]+), ?сез"
],
"episode_num": [
"епизод ([0-9]+)",
"еп. ([0-9]+)",
"[, ] ([0-9]+) епизод",
"с. ([0-9]+)$"
],
"airdate": [
", ([0-9][0-9][0-9][0-9])"
]
}
Updated by Em Smith almost 9 years ago
Parsing content type is quite different code since it reads a string but has to convert it to a specific category number internally. I have to read the code more to learn how the config can be read and the exact numbers used.
Updated by saen acro almost 9 years ago
документален филм, 5 епизод
e5 not set
сезон 4, епизод 12, криминален, драма, САЩ, 2016
s04.e12 set correctly.
Isn't more correct to set as
S04.E12 upper case letters, dot between... am not sure is it needed.
Updated by Em Smith almost 9 years ago
I don't know why "документален филм, 5 епизод" isn't matched. It matches the configuration line "[, ] ([0-9]+) епизод" when I try it here. Perhaps it has not rescanned that channel yet?
The epg database file is in ".hts/tvheadend/epgdb.v2" (I don't know where that is on your system). If you stop tvheadend, remove file, restart tvheadend you will have no EPG and can rescan and see if it works.
If that does not work, the other reason it can fail is I had two updates giving different description for the same programme, one did not have episode information so it kept removing episode data. If rescan does not work I can give you a patch to log if that happens for you.
I agree with S04.E12 or S04E12, but existing GUI logic uses lowercase. I think it might be considered easier to read.
Updated by saen acro almost 9 years ago
If i get correct logic, it expect to be a first value in string.
But in case is second.
Updated by Em Smith almost 9 years ago
Tvheadend tries each line in "episode_num" and uses the first that works.
So "сезон 4, епизод 12, криминален, драма, САЩ, 2016" matches line 1 "епизод ([0-9]+)" (епизод followed by a space followed by digits).
But "документален филм, 5 епизод" matches line 3 "[, ] ([0-9]+) епизод" (a comma or a space followed by digits followed by space followed by епизод).
If the rescan does not work, is there anything different for this fail? Is it in a different part of the programme info? If you press "EPG->fulltext" and paste "[, ] ([0-9]+) епизод" (without the ") does it match anything?
Updated by Em Smith almost 9 years ago
- File Bulsatcom_39E Bulsatcom_39E added
Try this file attached file directly. Perhaps the pasted text above changed the spacing.
Updated by saen acro almost 9 years ago
NO change, it's same.
документален филм, 5 епизод, повторение анимационен филм, 7 епизод
This type of string are not parsed :(
Some how
"Value A, VAleue №, Value C"
"Value A, VAleue №" string are not parsed
but if
"Value №, Value X, Value Y" string are working
difference is only in position
 Updated by Mark Clarkstone almost 9 years ago
Updated by Mark Clarkstone almost 9 years ago
@Em Smith, would you like me to up the priority of this issue so that more people see it? Allowing them to request additional scrapers?
Also, instead of a text input box for the scraper selection, how about a drop down with the available scrapers instead?
 Updated by Petar Ivanov almost 9 years ago
Updated by Petar Ivanov almost 9 years ago
My type work, but not show: с. 1 and сезон 4 when are alone, when have season and series same time show.
I remove с. ([0-9]+)$ from episode_num, because this is mean season.
{
"season_num": [
"сезон ([0-9]+)",
"[, ] сезон ([0-9]+)",
"сез.? ([0-9]+)",
"[, ] с. ([0-9]+)",
"с. ([0-9]+), еп.",
"с. ([0-9]+)",
"еп. [0-9]+,.*, ([0-9]+), ?сез"
],
"episode_num": [
"([0-9]+) серия",
"еп. ([0-9]+)",
"[, ] ([0-9]+) еп.",
"([0-9]+) еп.[,]",
"епизод ([0-9]+)",
"Епизод ([0-9]+)",
"[, ] ([0-9]+) епизод",
"([0-9]+) епизод"
],
"airdate": [
", ([0-9][0-9][0-9][0-9])"
]
}
Updated by saen acro almost 9 years ago
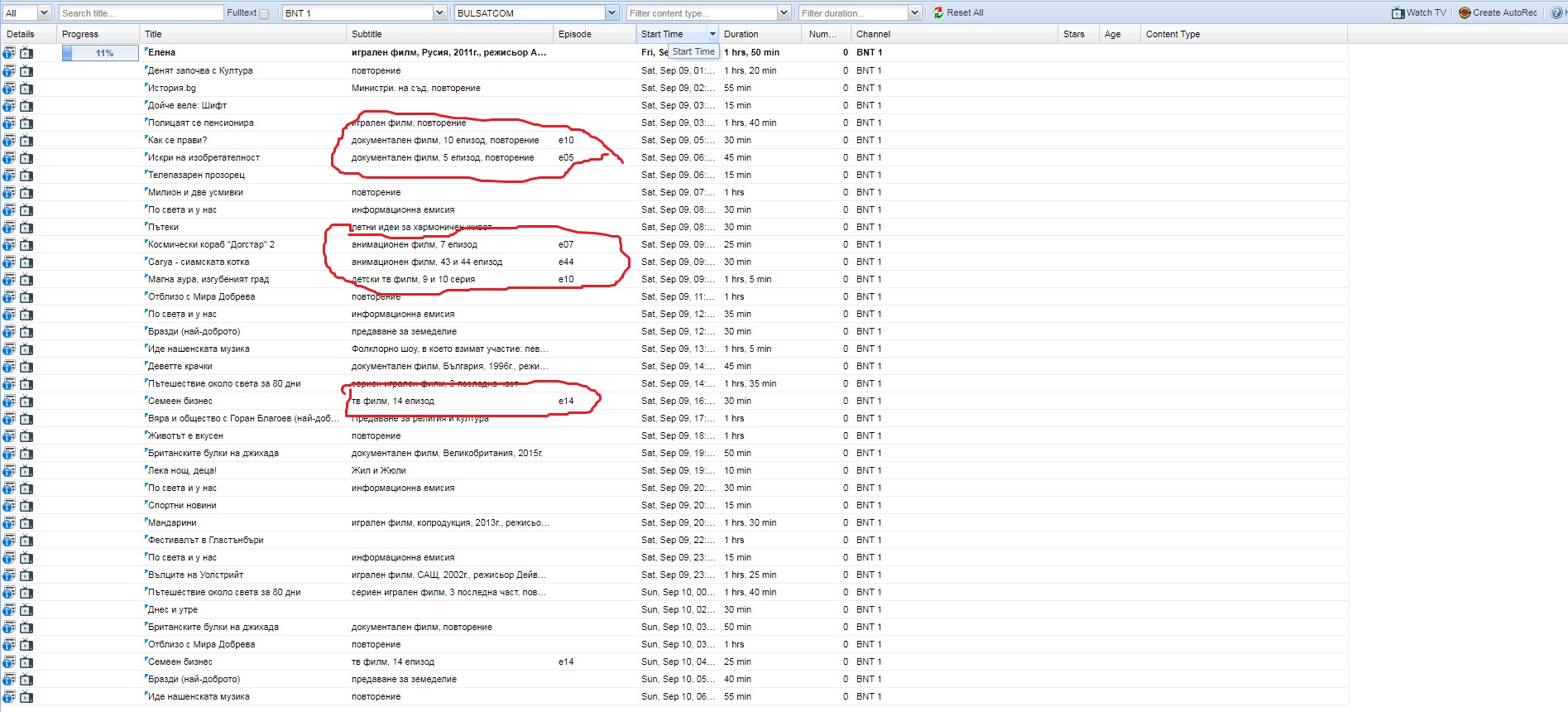
This also do not help
Peter you can check BNT 1
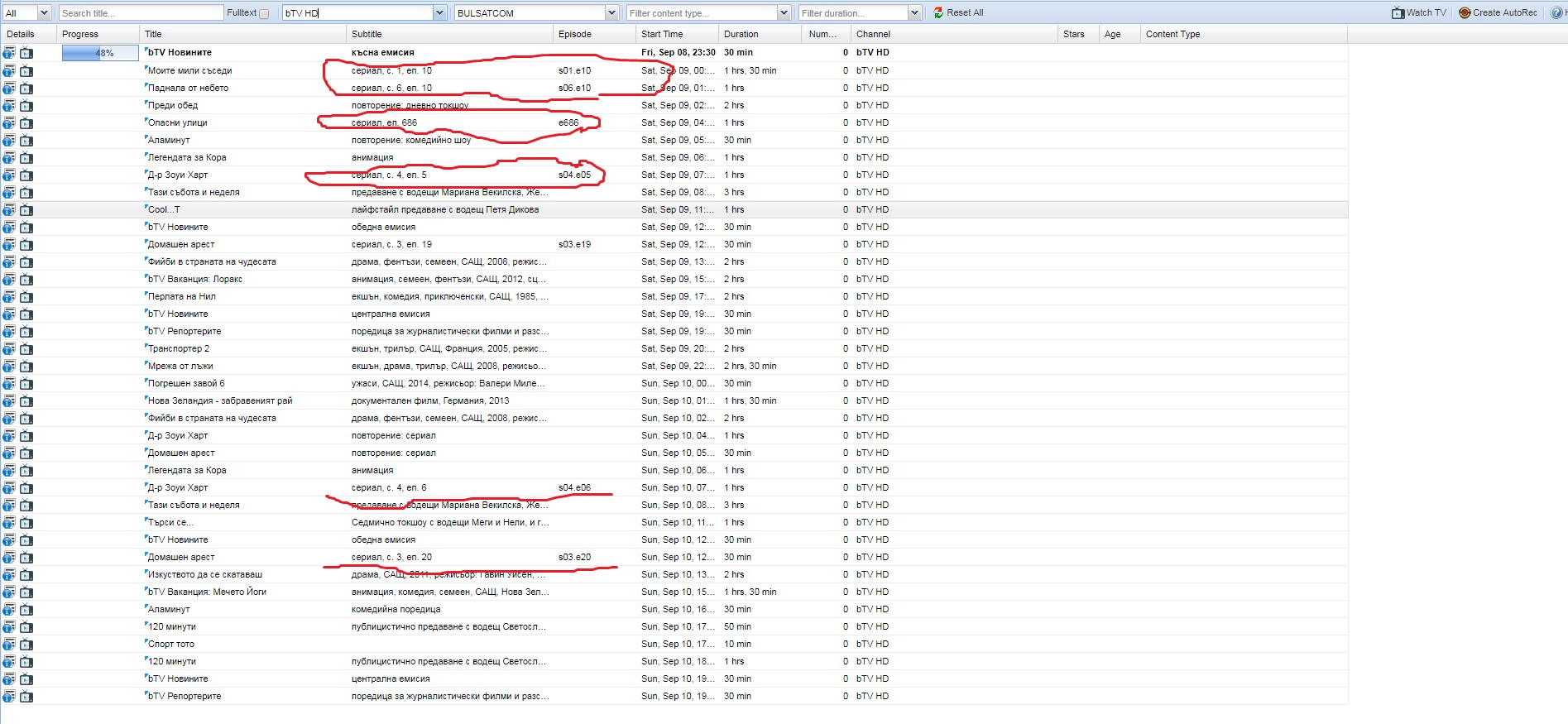
bTV have series without season
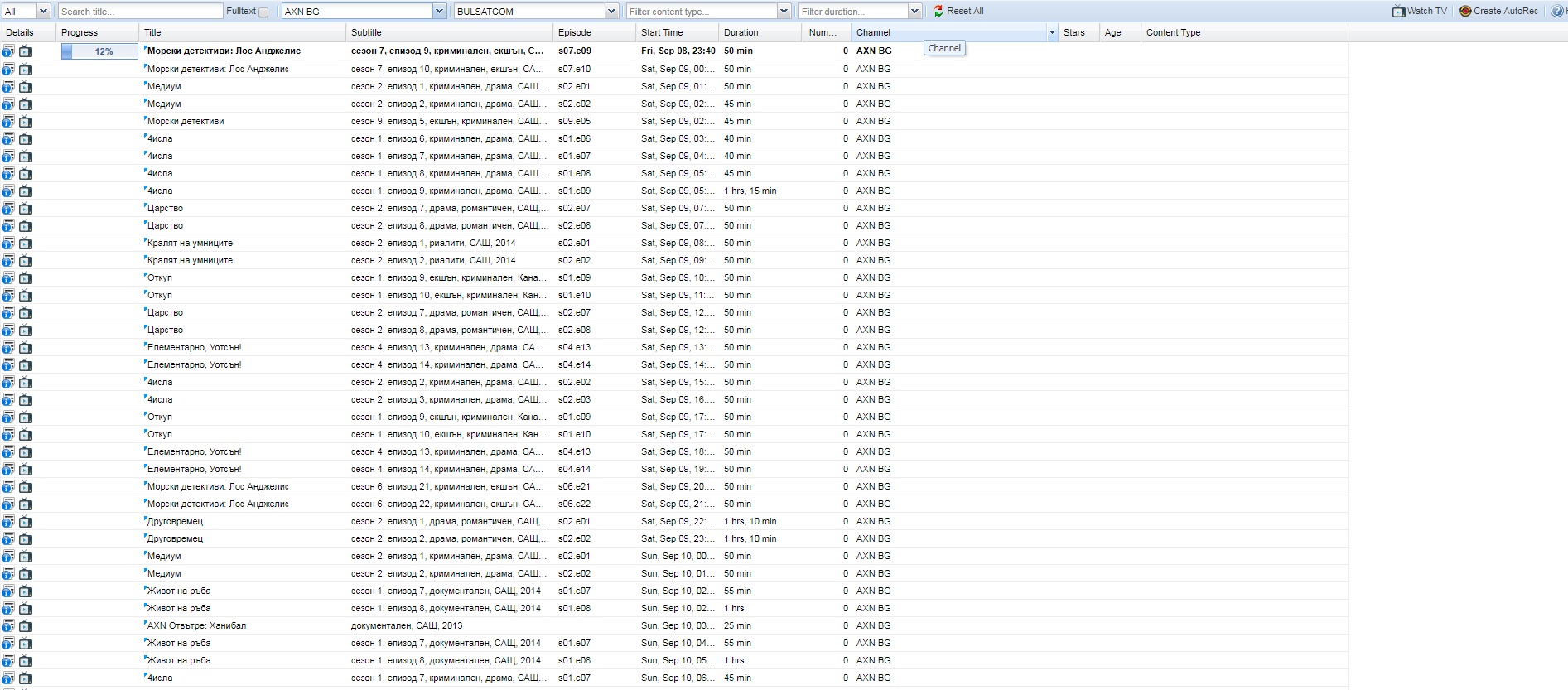
AXN works perfect
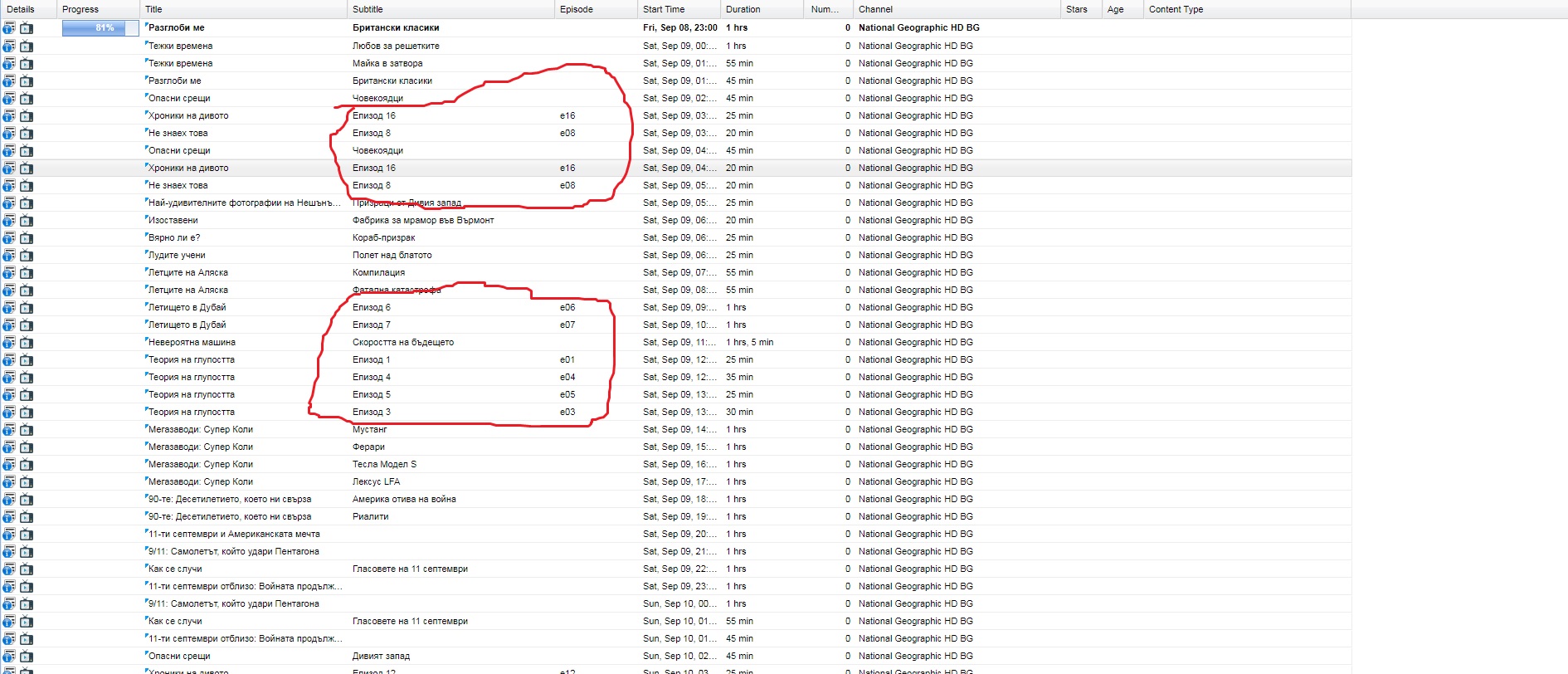
Updated by Petar Ivanov almost 9 years ago
- File BNT 1.jpg BNT 1.jpg added
- File Nat Geo.jpg Nat Geo.jpg added
- File btv comedy.jpg btv comedy.jpg added
- File AXN.jpg AXN.jpg added
- File BTV.jpg BTV.jpg added
I say this here work on BNT 1, but not work when is only с. 1
See screenshots
Updated by Petar Ivanov almost 9 years ago
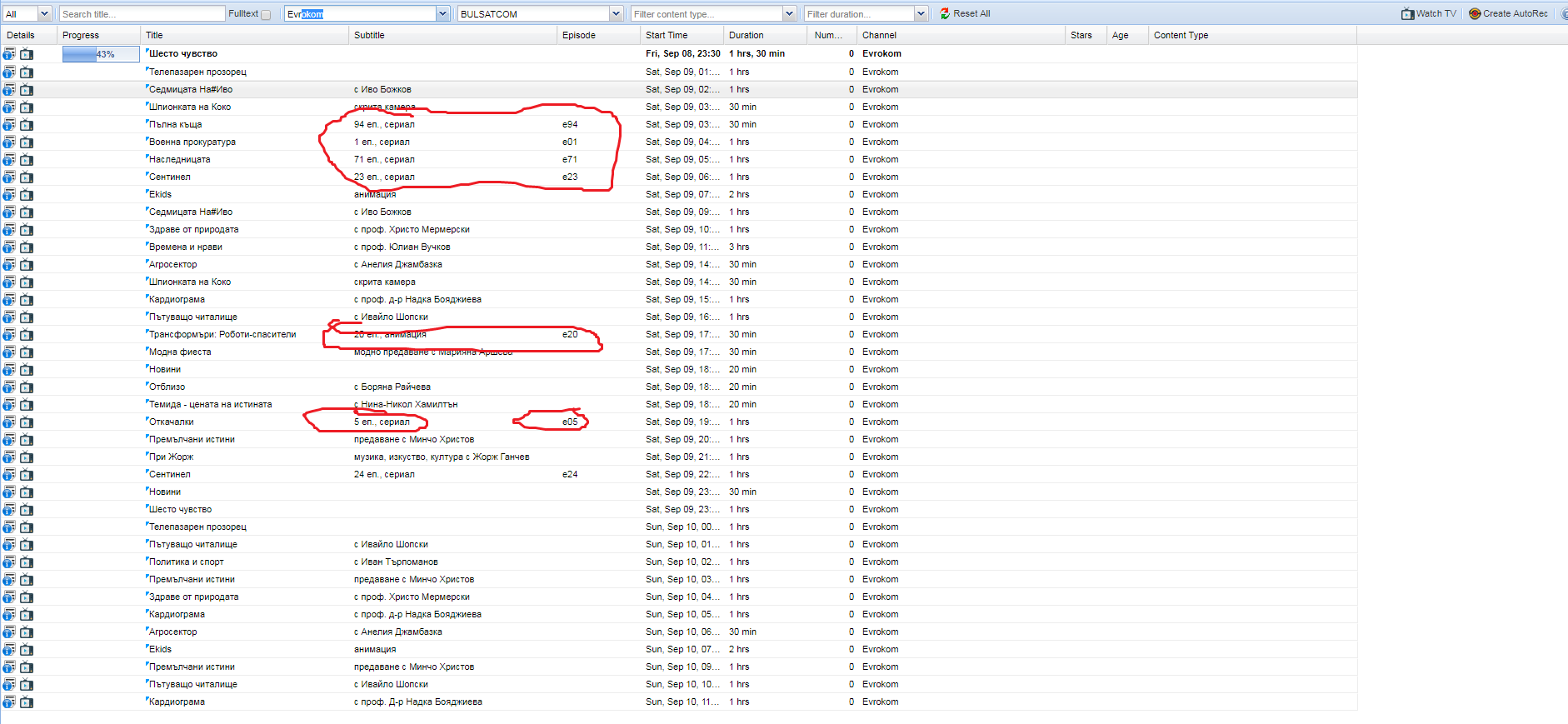
- File Evrokom.png Evrokom.png added
- File kinonova.jpg kinonova.jpg added
- File hobby tv hd.jpg hobby tv hd.jpg added
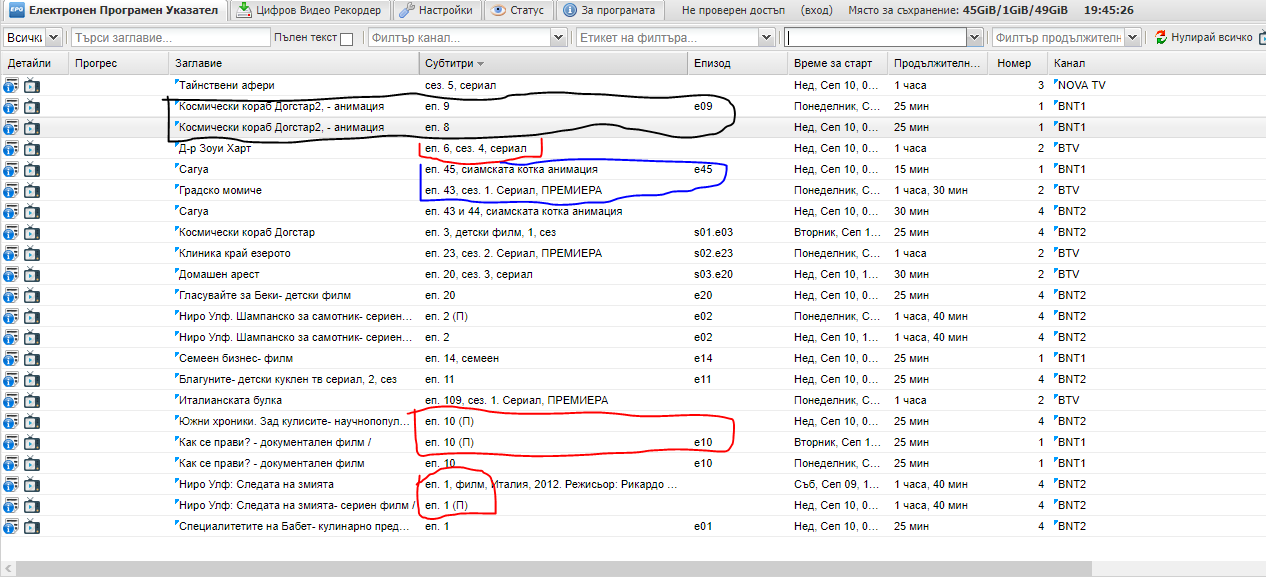
Not work when have Сесон and short с. srennshot in KinoNova and btv comedy, other wok
Updated by Em Smith almost 9 years ago
@Mark Clarkstone
I like the drop-down idea. It would make it easier to configure for people. I'll have to find an example in the code where it's dynamically generated.
I think if we leave the priority for the moment, get the search to also go across subtitle&description change in proposed by Konermann in #4287 and the test harness in #4577, and let early adopters see if there is any fallout that requires changes before advertising it more and getting more config.
Updated by saen acro almost 9 years ago
Just found something wrong
кулинарно предаване, 3 епизода
literally is written that there will be played tree series,
also time respond to this, but scrapper thing S03
Updated by saen acro almost 9 years ago
Also some strings for age rating
еп. 7, комедия, САЩ, 2017. В ролите: Иса Рей, Ивон Орджи, Джей Елис, Лиса Джойс, Наташа Ротуел, [15+]
[15+] is rating
How do I have to fill in convertor "First|second|third|forth|fifth|..."
in my case "първи|втори|трети|четвърти|пети|..."
for converting season number?
Airdate, is this work?
Updated by Em Smith almost 9 years ago
Unfortunately I can't scrape the first, second since it requires a string to number lookup (same as genre). Does first, second occur a lot?
Airdate may work. I tried to write it so it matches for examples you gave. I can't see any easy way for a user to verify it works since Kodi doesn't seem to display it.
Rating is interesting. I will look if the code can handle that. Is it always in the same format "[18+]", "[15+]", etc? What about children programmes are they "[7+]"?
Updated by saen acro almost 9 years ago
IF I change Line
"[, ] ([0-9]+) епизод",
to
"[, ] ([0-9]+) епизод [, ]",
is this will exclude
word "епизода" from string
кулинарно предаване, 3 епизода
Updated by Em Smith almost 9 years ago
Are you using Petar Ivanov's changes from above? If yes, then it will match line 3 in season of '"[, ] ([0-9]+) еп."'.
The "еп." should be "еп[.]" in his file since "." means "any character".
But it will then match the last two lines.
So "кулинарно предаване, 3 епизода" is "cookery show, with episode number of 3 (E3)", or does it mean "total number of episodes is 3"?
Earlier (comment 14) you said "документален филм, 5 епизод" should mean "documentary, Episode 5"?
So it's not matching any episode?
I'm adding all the examples you and Petar have to my tests and hopefully we can get it solved.
Easiest way to test your changes is to use 'echo' for the string you have and 'egrep' with the string bit. If it returns nothing then it does not match. If it returns something (maybe highlighted in red) then it has matched.
echo "кулинарно предаване, 3 епизода" | egrep "[, ] ([0-9]+) епизод "
@Petar:
For BNT1, do you mean it should be "S1.E10", "S1.E05" for the first two examples in BNT1.jpg?
At the moment, we do not force a season if broadcast does not have one. Does it make sense to always force season 1 if you have an episode and no season? (In my region you often have Ep1 even though it might be S3 and they don't say it is S3).
For kinonova, first line should be S4?
Updated by saen acro almost 9 years ago
Em Smith wrote:
Are you using Petar Ivanov's changes from above? If yes, then it will match line 3 in season of '"[, ] ([0-9]+) еп."'.
The "еп." should be "еп[.]" in his file since "." means "any character".
Dot meaning is same as "ex." from "example"
But it will then match the last two lines.
So "кулинарно предаване, 3 епизода" is "cookery show, with episode number of 3 (E3)", or does it mean "total number of episodes is 3"?
Earlier (comment 14) you said "документален филм, 5 епизод" should mean "documentary, Episode 5"?
So it's not matching any episode?
I'm adding all the examples you and Petar have to my tests and hopefully we can get it solved.
Easiest way to test your changes is to use 'echo' for the string you have and 'egrep' with the string bit. If it returns nothing then it does not match. If it returns something (maybe highlighted in red) then it has matched.
[echo "кулинарно предаване, 3 епизода" | egrep "[, ] ([0-9]+) епизод "]
:~$ echo "кулинарно предаване, 3 епизода" | egrep "[, ] ([0-9]+) епизод " :~$ echo "кулинарно предаване, 3 епизод" | egrep "[, ] ([0-9]+) епизод "
:~$ echo "кулинарно предаване, 3 епизод" | egrep "[, ] ([0-9]+) епизод"
кулинарно предаване, 3 епизод
:~$ echo "кулинарно предаване, 3 епизода" | egrep "[, ] ([0-9]+) епизод"
кулинарно предаване, 3 епизода
Updated by saen acro almost 9 years ago
- File Заснемане11.PNG Заснемане11.PNG added
my file
{
"season_num": [
"сезон ([0-9]+)",
"[, ] сезон ([0-9]+)",
"сез.? ([0-9]+)",
"[, ] с[.] ([0-9]+)",
"с[.] ([0-9]+), еп.",
"с[.] ([0-9]+)",
"еп[.] [0-9]+,.*, ([0-9]+), ?сез"
],
"episode_num": [
"([0-9]+) серия ",
"еп[.] ([0-9]+) ",
"[, ] ([0-9]+) еп.",
"([0-9]+) еп[.][,]",
"епизод ([0-9]+)",
"Епизод ([0-9]+)",
"[, ] ([0-9]+) епизод ",
"([0-9]+) епизод "
],
"airdate": [
", ([0-9][0-9][0-9][0-9])"
]
}
result attached
Updated by Em Smith almost 9 years ago
I've submitted a pull request for a test harness (#4577). This has a simple file where you can put the EIT description and what you expect season and episode to be to check your changes.
In the config file "." means "any character" (rather than ex. as in example). I think it was my mistake that has been copied.
For example this egrep will match the character "е":
$ echo "кулинарно предаване, 3 епизода" | egrep "пр.да" кулинарно предаване, 3 епизода
My test harness suggests your config file does not parse this from your earlier example in comment 27: "еп. 7, комедия, САЩ".
Perhaps instead of "еп[.] ([0-9]+) " try "еп[.] ([0-9]+)[ ,]" (which means space or comma).
Updated by Em Smith almost 9 years ago
The test harness (#4577) is now available, so let's try and get this config working as best we can. We might not get 100% season/episode working, but let's try our best.
The file in support/testdata/eitscrape/bg contains examples from your bug reports, so "summary" is the text from EIT, "season" and "episode" are what you expect to receive, with "null" meaning don't expect anything.
cd support PYTHONIOENCODING=utf-8 ./eitscrape_test.py ../data/conf/epggrab/eit/scrape/Bulsatcom_39E ./testdata/eitscrape/bg
So over the next few days, please try and add other examples that work or don't work. Just add them to the support/testdata/eitscrape/bg test file and re-run the test harness to see if it works.
Then next weekend let's try and get the best config.
Updated by saen acro almost 9 years ago
- File channels.7z channels.7z added
This is export of current moment EPG,
How do I can use script on it?
Updated by Em Smith almost 9 years ago
That file is actually really useful. For example I can see lots of odd things such as:
<sub-title lang="bul">еп. 78 </sub-title>
(78 followed by two spaces, which I would never have known from the screenshot);
and
<desc lang="bul"> Сенките...
(space immediately before the description, but only for some programmes).
We can't use the file directly, but can copy+paste to make examples. For example if your GUI isn't showing a correct season/episode then find the information in your channels file and use it.
There exists the file "support/testdata/eitscrape/bg"
For example:
In your file channels.7z, search in the file for "сезон 2, епизод 4, драма, криминален, САЩ, 2015" and you will find:
<sub-title lang="bul">сезон 2, епизод 4, драма, криминален, САЩ, 2015 </sub-title>
If we assumed that wasn't working then we would add an entry via copy+paste (ensure we get everything, including extra spaces):
{
"summary": "сезон 2, епизод 4, драма, криминален, САЩ, 2015 ",
"season" : 2, "episode": "4", "airdate" : "2015"
},
Then we run the test harness:
cd support; PYTHONIOENCODING=utf-8 ./eitscrape_test.py ../data/conf/epggrab/eit/scrape/Bulsatcom_39E ./testdata/eitscrape/bg
(Assuming your regex file is called Bulsatcom_39E in that directory).
And you should see at the end NumOK: XX NumFailed: YY
So then we know if it worked or not and can alter the regex to try and match it.
Now, we don't actually need that as a new entry since I already have one very similar in the test file. But hopefully that gives an idea.
Updated by Em Smith almost 9 years ago
- File 0001-eit-Scrape-genre-from-text-in-OTA-EIT.-4509.patch 0001-eit-Scrape-genre-from-text-in-OTA-EIT.-4509.patch added
I've attached a patch for converting genre strings. My broadcaster sends content type, but I've tested the patch by forcing specific programmes to have a different genre.
You need to alter your scraper configuration file and add section such as:
"genre_16": ["(драма, романтичен)"],
"genre_23": ["(документален)"]
The codes at the end are the content specifier (hex) value from EN 300 468 table 28.
[[http://www.etsi.org/deliver/etsi_en/300400_300499/300468/01.11.01_60/en_300468v011101p.pdf]]
Each regex needs brackets to indicate it's a "match". You can have multiple regex per genre, or combine them such as "(a|b)".
You can apply the patch via "git am file.patch".
The configuration file I have for Bulsatcom episodes still has a problem with not recognizing "кулинарно предаване, 3 епизода". Did you create a better file?
Let me know if it you have questions.
Updated by saen acro almost 9 years ago
Em Smith wrote:
The configuration file I have for Bulsatcom episodes still has a problem with not recognizing "кулинарно предаване, 3 епизода". Did you create a better file?
this must be excluded can not be recognized tree episodes they can be 1, 2, 3 or 256, 257, 258
----
Translations table
ETSI EN 300 468 V1.11.1 (2010-04)
Table 28: Content_nibble level 1 and 2 assignments
| Content_nibble_level_1 | Content_nibble_level_2 | ID | Description |
|---|---|---|---|
| Movie/Drama: | |||
| 0x1 | 0x0 | 10 | movie/drama (general) |
| 0x1 | 0x1 | 11 | detective/thriller |
| 0x1 | 0x2 | 12 | adventure/western/war |
| 0x1 | 0x3 | 13 | science fiction/fantasy/horror |
| 0x1 | 0x4 | 14 | comedy |
| 0x1 | 0x5 | 15 | soap/melodrama/folkloric |
| 0x1 | 0x6 | 16 | romance |
| 0x1 | 0x7 | 17 | serious/classical/religious/historical movie/drama |
| 0x1 | 0x8 | 18 | adult movie/drama |
| News/Current affairs: | |||
| 0x2 | 0x0 | 20 | news/current affairs (general) |
| 0x2 | 0x1 | 21 | news/weather report |
| 0x2 | 0x2 | 22 | news magazine |
| 0x2 | 0x3 | 23 | documentary |
| 0x2 | 0x4 | 24 | discussion/interview/debate |
| Show/Game show: | |||
| 0x3 | 0x0 | 30 | show/game show (general) |
| 0x3 | 0x1 | 31 | game show/quiz/contest |
| 0x3 | 0x2 | 32 | variety show |
| 0x3 | 0x3 | 33 | talk show |
| Sports: | |||
| 0x4 | 0x0 | 40 | sports (general) |
| 0x4 | 0x1 | 41 | special events (Olympic Games, World Cup, etc.) |
| 0x4 | 0x2 | 42 | sports magazines |
| 0x4 | 0x3 | 43 | football/soccer |
| 0x4 | 0x4 | 44 | tennis/squash |
| 0x4 | 0x5 | 45 | team sports (excluding football) |
| 0x4 | 0x6 | 46 | athletics |
| 0x4 | 0x7 | 47 | motor sport |
| 0x4 | 0x8 | 48 | water sport |
| 0x4 | 0x9 | 49 | winter sports |
| 0x4 | 0xA | 4a | equestrian |
| 0x4 | 0xB | 4b | martial sports |
| Children's/Youth programmes: | |||
| 0x5 | 0x0 | 50 | children's/youth programmes (general) |
| 0x5 | 0x1 | 51 | pre-school children's programmes |
| 0x5 | 0x2 | 52 | entertainment programmes for 6 to14 |
| 0x5 | 0x3 | 53 | entertainment programmes for 10 to 16 |
| 0x5 | 0x4 | 54 | informational/educational/school programmes |
| 0x5 | 0x5 | 55 | cartoons/puppets |
| Music/Ballet/Dance: | |||
| 0x6 | 0x0 | 60 | music/ballet/dance (general) |
| 0x6 | 0x1 | 61 | rock/pop |
| 0x6 | 0x2 | 62 | serious music/classical music |
| 0x6 | 0x3 | 63 | folk/traditional music |
| 0x6 | 0x4 | 64 | jazz |
| 0x6 | 0x5 | 65 | musical/opera |
| 0x6 | 0x6 | 66 | ballet |
| Arts/Culture (without music): | |||
| 0x7 | 0x0 | 70 | arts/culture (without music, general) |
| 0x7 | 0x1 | 71 | performing arts |
| 0x7 | 0x2 | 72 | fine arts |
| 0x7 | 0x3 | 73 | religion |
| 0x7 | 0x4 | 74 | popular culture/traditional arts |
| 0x7 | 0x5 | 75 | literature |
| 0x7 | 0x6 | 76 | film/cinema |
| 0x7 | 0x7 | 77 | experimental film/video |
| 0x7 | 0x8 | 78 | broadcasting/press |
| 0x7 | 0x9 | 79 | new media |
| 0x7 | 0xA | 7a | arts/culture magazines |
| 0x7 | 0xB | 7b | fashion |
| Social/Political issues/Economics: | |||
| 0x8 | 0x0 | 80 | social/political issues/economics (general) |
| 0x8 | 0x1 | 81 | magazines/reports/documentary |
| 0x8 | 0x2 | 82 | economics/social advisory |
| 0x8 | 0x3 | 83 | remarkable people |
| Education/Science/Factual topics: | |||
| 0x9 | 0x0 | 90 | education/science/factual topics (general) |
| 0x9 | 0x1 | 91 | nature/animals/environment |
| 0x9 | 0x2 | 92 | technology/natural sciences |
| 0x9 | 0x3 | 93 | medicine/physiology/psychology |
| 0x9 | 0x4 | 94 | foreign countries/expeditions |
| 0x9 | 0x5 | 95 | social/spiritual sciences |
| 0x9 | 0x6 | 96 | further education |
| 0x9 | 0x7 | 97 | languages |
| Leisure hobbies: | |||
| 0xA | 0x0 | a0 | leisure hobbies (general) |
| 0xA | 0x1 | a1 | tourism/travel |
| 0xA | 0x2 | a2 | handicraft |
| 0xA | 0x3 | a3 | motoring |
| 0xA | 0x4 | a4 | fitness and health |
| 0xA | 0x5 | a5 | cooking |
| 0xA | 0x6 | a6 | advertisement/shopping |
| 0xA | 0x7 | a7 | gardening |
| Special characteristics: | |||
| 0xB | 0x0 | b0 | original language |
| 0xB | 0x1 | b1 | black and white |
| 0xB | 0x2 | b2 | unpublished |
| 0xB | 0x3 | b3 | live broadcast |
also to be easy to be translated to other languages
genre_10": ["(movie/drama (general)"], genre_11": ["(detective/thriller"], genre_12": ["(adventure/western/war"], genre_13": ["(science fiction/fantasy/horror"], genre_14": ["(comedy"], genre_15": ["(soap/melodrama/folkloric"], genre_16": ["(romance"], genre_17": ["(serious/classical/religious/historical movie/drama"], genre_18": ["(adult movie/drama"], genre_20": ["(news/current affairs (general)"], genre_21": ["(news/weather report"], genre_22": ["(news magazine"], genre_23": ["(documentary"], genre_24": ["(discussion/interview/debate"], genre_30": ["(show/game show (general)"], genre_31": ["(game show/quiz/contest"], genre_32": ["(variety show"], genre_33": ["(talk show"], genre_40": ["(sports (general)"], genre_41": ["(special events (Olympic Games, World Cup, etc.)"], genre_42": ["(sports magazines"], genre_43": ["(football/soccer"], genre_44": ["(tennis/squash"], genre_45": ["(team sports (excluding football)"], genre_46": ["(athletics"], genre_47": ["(motor sport"], genre_48": ["(water sport"], genre_49": ["(winter sports"], genre_4a": ["(equestrian"], genre_4b": ["(martial sports"], genre_50": ["(children's/youth programmes (general)"], genre_51": ["(pre-school children's programmes"], genre_52": ["(entertainment programmes for 6 to14"], genre_53": ["(entertainment programmes for 10 to 16"], genre_54": ["(informational/educational/school programmes"], genre_55": ["(cartoons/puppets"], genre_60": ["(music/ballet/dance (general)"], genre_61": ["(rock/pop"], genre_62": ["(serious music/classical music"], genre_63": ["(folk/traditional music"], genre_64": ["(jazz"], genre_65": ["(musical/opera"], genre_66": ["(ballet"], genre_70": ["(arts/culture (without music, general)"], genre_71": ["(performing arts"], genre_72": ["(fine arts"], genre_73": ["(religion"], genre_74": ["(popular culture/traditional arts"], genre_75": ["(literature"], genre_76": ["(film/cinema"], genre_77": ["(experimental film/video"], genre_78": ["(broadcasting/press"], genre_79": ["(new media"], genre_7a": ["(arts/culture magazines"], genre_7b": ["(fashion"], genre_80": ["(social/political issues/economics (general)"], genre_81": ["(magazines/reports/documentary"], genre_82": ["(economics/social advisory"], genre_83": ["(remarkable people"], genre_90": ["(education/science/factual topics (general)"], genre_91": ["(nature/animals/environment"], genre_92": ["(technology/natural sciences"], genre_93": ["(medicine/physiology/psychology"], genre_94": ["(foreign countries/expeditions"], genre_95": ["(social/spiritual sciences"], genre_96": ["(further education"], genre_97": ["(languages"], genre_a0": ["(leisure hobbies (general)"], genre_a1": ["(tourism/travel"], genre_a2": ["(handicraft"], genre_a3": ["(motoring"], genre_a4": ["(fitness and health"], genre_a5": ["(cooking"], genre_a6": ["(advertisement/shopping"], genre_a7": ["(gardening"], genre_b0": ["(original language"], genre_b1": ["(black and white"], genre_b2": ["(unpublished"], genre_b3": ["(live broadcast"],
Updated by Em Smith almost 9 years ago
I think there's a misunderstanding. The genre names are already translated in tvheadend.bg.po, so you will probably already have Мониторинг, Изящни изкуства, etc. in the GUI.
The regex that you need to put in the configuration file need to match your broadcast data such as those in comment 1 such as Заснемане.PNG and Заснемане2.PNG that are in your sub-title.
So from those images you could have regex such as:
"genre_10" : ["(^Драма, )"], "genre_12" : ["(, Фантастични, )"], "genre_14" : ["(^Комедия)"],
Updated by saen acro over 8 years ago
Em Smith wrote:
I think there's a misunderstanding. The genre names are already translated in tvheadend.bg.po, so you will probably already have Мониторинг, Изящни изкуства, etc. in the GUI.
The regex that you need to put in the configuration file need to match your broadcast data such as those in comment 1 such as Заснемане.PNG and Заснемане2.PNG that are in your sub-title.
So from those images you could have regex such as:
[...]
Em Smith can you describe steps with epg string take during parsing.
how words are sorted and pass to coresponding values in epg table in UI.
(diagram or somting)
p.s.
Мониторинг = Monitoring ;)
also is reading and sounds same ;)
Updated by Em Smith over 8 years ago
The idea is that if "genre_xy" matches a regular expression then the programme will be assigned genre category code "xy".
So, if genre_10 has regex "(^Драма, )" then if your programme has "Драма" it will be given internally genre code 10.
The regex is only used for matching, the actual words it matches are not used. So, if you match against "(^Драма, )" then that word is not used, it is the category code ("genre_xy") that is used.
With other countries the DVB contains multiple genre codes so we simply copy them to internal structures. The regex in the patch connects to that logic.
If a programme matches multiple regex then it will be given multiple genres.
If you add the examples I gave an run an OTA grab then you should be able to use "filter by content type" on EPG which may make it more clear what is happening.
Updated by saen acro over 8 years ago
I still believe that simple CSV table will be better solution for parsing genre type.
ex.| CODE | ETSI Description | language EN | language BG | language IT | language DE | language PL |
|---|---|---|---|---|---|---|
| 14 | comedy | comedy | комедия | commedia | Komödie | komedia |
Everybody can translate corresponding colon to his language.
And when parser see word "Комедия" between or fallowed by coma , Комедия, to search VAriables loaded per corresponding language colon to find word "Комедия" and set value in EPG genre for Event.
Sorry for stupid explaining but I programmed only on Basic, but don't belie in modern programming languages, is harder to GET/SET values after IF/THEN/ELSE logic.
p.s. is small and capital letters are differently taken
is Комедия = комедия?
Updated by Em Smith over 8 years ago
The patterns are case-sensitive (small and capital letters are different). I couldn't find any obvious documentation for how it would handle insensitive regex locales (e.g., German ß) since it uses an older regex library to keep compatibility with systems that do not ship/build with the more powerful (but optional) pcre regex libraries. You can probably use "[Кк]омедия" to match both patterns.
The CSV is less flexible because the regex is not per-language but per-region. For example, satellite in UK has completely different text in title/description to satellite in USA despite both being EN.
But, more importantly, many broadcasters already transmit the genre code as part of the data so drama is already tagged, and adding regex for those systems could be wrong since regex matching is not as accurate as broadcaster's knowledge of what they are broadcasting.
You see a similar per-region approach in language translation files where each region has its own file instead of all language being in one file.
Another reason is that CSV files are quite difficult for developer merges since merges occur on a line-by-line basis and you get frequent conflicts.
The advantage of the config-based approach is that you don't have to define all genres if you don't want to, just define the major ones (10, 20, 30, etc) and ignore the minor ones (21, 22, 23).
Updated by saen acro over 8 years ago
CSV can be used only to load variables once, not to make each ask from file (memory is little faster ;) )
All symbols ñåüúíóöøðßáæ etc. is part of utf8 (ISO-8859-(1-15) need just to be converted)
 Updated by Jaroslav Kysela over 8 years ago
Updated by Jaroslav Kysela over 8 years ago
I believe that we should extend the genres to new three or four level ETSI TS 102 822-3-1 format, see #3753 before this code.
Also, it would be probably much readable to use the english names as keys for the json config files like:
{
"Documentary": ["(документален)"]
}
Updated by saen acro over 8 years ago
Jaroslav Kysela wrote:
"Documentary": ["(документален)"]I believe that we should extend the genres to new three or four level ETSI TS 102 822-3-1 format, see #3753 before this code.
Also, it would be probably much readable to use the english names as keys for the json config files like:
{
}
In some situations there is a synonyms names for "news" from two words "новинарска емисия", "вечерни новини" etc.
So we need some easy to fill text file, human readable/editable
I'll be very happy if UI option appeared
Updated by Em Smith over 8 years ago
The ETSI categories are far more comprehensive and seem to be what I get in SD and parse out as categories. It's a shame their major numbers aren't compatible with the EN300468 numbers (so 3.1.1 for News vs 0x20). The one problem I see is that so many clients seem to hardcode the major/minor genre extraction, primarily to get colours in the EPG GUI. It looks like Kodi has EPG_GENRE_USE_STRING and so it can pass through arbitrary data.
I think if we proceed with this patch then the config file should probably move all the genre tags in to a sub-tag map to keep them all nicely together (so have genres : [ genre_ab: [], genre_cd: [] ]).
I thought about using string names. The code should be easy (maybe 50 lines) but I thought it might be too complicated for config files and typos. It's ok for some genres ("religion", "athletics") but since we have genres such as "special events (Olympic Games, World Cup, etc.)" it would be too difficult for people to type. So then we'd have to have to have shortened names. I thought perhaps the numbers since it's then easy to see which genres are missing, e.g., if we have 40, 44, 45, then it's clear we are missing 41-43. However, I'm easy on adding it, or having both formats.
But with ETSI, the numbering is more difficult to read. Would we have "Religion/Philosophies" (3.1.2) and then append the sub-category "Religion" (3.1.2.1) and sub-sub-category "Buddhism" (3.1.2.1.1) to get "Religion/Philosophies/Religion/Buddhism"?
I don't think this needs a GUI nor a new config file format since I think all Tvheadend config is JSON. It is a system file that is likely to be modified only a couple of times a year at most. Even then, the mapping is only useful for broadcasters that don't send genre information but have data that is scrapable. Examples of existing config such as data/conf/epggrab/opentv/dict/skyeng. It's certainly possible to post-process some other easier-to-edit format in to JSON, which suggests that perhaps this config should be in a completely separate file.
I'll park this one pending #3573 and more agreement on the best way forward.
Updated by saen acro over 8 years ago
Em Smith wrote:
I've attached a patch for converting genre strings. My broadcaster sends content type, but I've tested the patch by forcing specific programmes to have a different genre.
Let me know if it you have questions.
This don't fill data
It's more easy to give account to my TVH to test.
Updated by Em Smith over 8 years ago
- File 0001-eit-Scrape-genre-from-text-in-OTA-EIT.-4509.patch 0001-eit-Scrape-genre-from-text-in-OTA-EIT.-4509.patch added
Sorry I missed your previous post.
It's taken a while since I needed to get some other bugs resolved first. Please try the new patch when you have time. The configuration has changed slightly so it is:
"genre" : [ {
"Romance" : ["(Romcom)"],
"Detective / Thriller": [ "(Detective)" ]
"Cartoons / Puppets": [ "(Muppets|Sesame)" ],
"Sports" : ["^(Snooker)"]
}]
You should see lines logged at startup:
"Module Bulsatcom_39E - Scrape "Detective / Thriller" to genre 0x11"
It doesn't use a separate file because of some slight complications with loading multiple different files. But hopefully they should be written once and then only modified very infrequently.
There's a few csv-to-json tools out there if it helps you.
There is a UK genre mapping file as an example.
The genre name must be English, the regex must have a capture group.
So:
"Documentary": ["(документален)"]
Not:
"Documentary": ["документален"] (Missing brackets)
Not:
"документален": ["(документален)"] (Left name must be English).
Also spaces are important in the left name, so "Detective / Thriller", not "Detective/Thriller" (missing space), not "Detective / thriller" (incorrect capital letters).
If it doesn't work then I'll add a bit more debug logging.
I think you have 50mbps but my Internet is still RFC 1149 so me debugging on your system may be a bit slow, so will try a bit of extra logging first.
Updated by saen acro over 8 years ago
Is there a way to process generated by TVH XMLTV xml file with this processing script?
regular scenario is slower.
----
P.S. about internet speed
I don't live in banana country (or western Europe) my internet is 10 time faster then 50Mbps,
nearly 30% households have fiber connection
Updated by Em Smith over 8 years ago
Perhaps csv is easier for generating the json? I've attached a quick script which uses exclamation mark ("!") as a separator instead of comma (",").
It will take a file like:
Romance!драма, романтичен Documentary!(документален) Detective / Thriller!(документален)
and it will add missing brackets and output this:
"genre" : [{
"Romance" : ["(драма, романтичен)"],
"Documentary" : ["(документален)"],
"Detective / Thriller" : ["(документален)"], <---you have to remove this comma yourself
}]
You can then copy+paste in to the Bulsatcom_39E file.
I already added a couple of examples in the Bulsatcom_39E file to see if it works for you.
500Mbps for 10euro? Compare UK 2016: "the slowest download speed was 0.12Mbps...the fastest average broadband speed at 77.17Mbps".
Updated by saen acro over 8 years ago
I try to patch but:
# patch <0001-eit-Scrape-genre-from-text-in-OTA-EIT.-4509.patch patching file Bulsatcom_39E can't find file to patch at input line 103 Perhaps you should have used the -p or --strip option? The text leading up to this was: -------------------------- |diff --git a/data/conf/epggrab/eit/scrape/uk b/data/conf/epggrab/eit/scrape/uk |index f7b383db0..bac2e8621 100644 |--- a/data/conf/epggrab/eit/scrape/uk |+++ b/data/conf/epggrab/eit/scrape/uk -------------------------- File to patch: /data/conf/epggrab/eit/scrape/uk /data/conf/epggrab/eit/scrape/uk: No such file or directory Skip this patch? [y]
Updated by Em Smith over 8 years ago
The patch is against master:
c1a5e434b59a0fa08e7a3c256ac6908fae2b0265
Thu Dec 14 21:28:22 2017 +0100
Updated by Em Smith over 8 years ago
Ah, actually you should use:
git am .....patch
(You can use git reset --hard HEAD^ to revert)
Updated by Em Smith over 8 years ago
The git reset command will delete all the changes from the patch including all changes you make to Bulsatcom_39E so take a copy of the config before resetting.
Updated by saen acro over 8 years ago
I make copy of Bulsatcom_39E to bg in
/usr/share/tvheadend/data/conf/epggrab/eit/scrape
but prefer to have copy here
https://github.com/tvheadend/tvheadend/tree/master/data/conf/epggrab/eit/scrape
Updated by Em Smith over 8 years ago
If the patch works for you, then I'll submit a Pull Request. If approved, the configuration will be in github. Then you can create the extra genre mappings and we can submit them as new configuration.
Then we should rename the "Bulsatcom_39E" grabber to "bg_bulsatcom" (to be consistent with the other grabbers) and the configuration file will be renamed "bg".